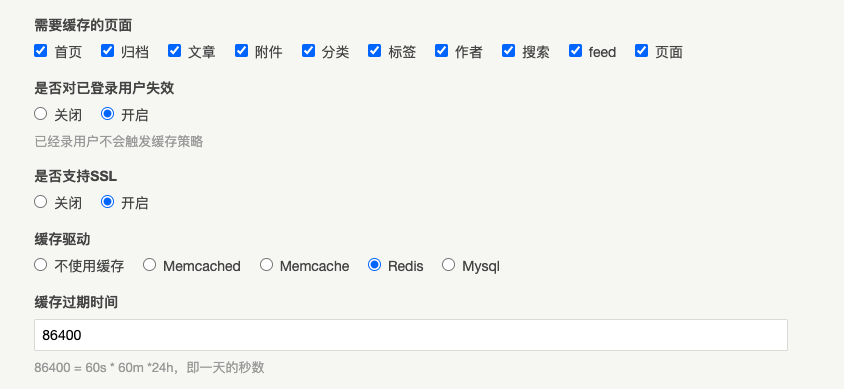
还记得这篇文章吗?一年前给博客做优化时使用到了 TpCache 这个插件,作者是 Phpgao;想来当时为了避免缓存会影响到文章阅读数统计,故而关掉了 缓存 页面/文章 的选项;

via 春潮频道;
I. 主理人序
本文的好处及麻烦,让 MySQL/PHP 不再受伤,让缓存好好扮演缓存;麻烦就是以下三个脚本写的不是很好,但逻辑上而言,还是很自洽的;
II. 思路
页面缓存的意义在于减少后端的读写,从而减轻服务器压力;这就意味着,页面被缓存后你再怎么刷新页面,都不会再有新的数据写入后端(如MySQL的数据库);即只会有 GET 请求,不会再有 POST 请求(参阅 GET 与 POST 的区别);
所以,此时我们应该将视线转移到 nginx 上来,access.log;lnmp,MySQL/PHP都唔得救了,那就从 nginx 上找方法吧,是的 还是会有日志的,用户(简单来说,一个用户就是一个IP地址,计为一个UV,刷次5次页面则计为5个PV)每一次浏览都会留下证据,从哪里来,访问了哪些页面等等;
我们要通过 access.log 统计一定时间范围内(泛指一天),访问的页面、对应的UV数,并将UV数与之前的页面浏览量加在一起,然后写入 MySQL后端数据(怎么写、都有包括哪些字段在后面会详细说明);
P.S. 博主的 TPCache 设置的 24小时清除一次缓存;另外,分析、抓取符合一定条件的日志时会使用到正则表达式(grep),希望大家对正则表达式有一定的了解;还有就是 MySQL 的一些命令,如查询、更新;嗯,以及 Crontab 定时脚本的使用;
不过大家可以放心,本文将会非常通俗易懂,操作起来逻辑性很强;
III. access.log 日志
鉴于过去一直潜在的DDoS/CC攻击,nginx 一直是有开启日志功能的,以便使用脚本统计一定时间范围内可能异常的IP访问及访问次数、访问页面等(他们啊刷我搜索,我就把搜索换成了谷歌自定义搜索),打了个寂寞;
Cloudlfare 下 nginx 获取用户真实IP地址
你们套了 Cloudflare CDN 吗?套了的话 参考下 Cloudflare 下 Nginx 获取用户真实IP 地址 这篇文章;
acess.log 日志切割
博主采用的是 lnmp.org 提供的日志切割脚本,参考:nginx日志切割脚本使用方法;
#!/bin/bash
#function:cut nginx log files for lnmp v0.5 and v0.6
#author: http://lnmp.org
#set the path to nginx log files
log_files_path="/home/wwwlogs/limbopro.com/"
log_files_dir=${log_files_path}$(date -d "yesterday" +"%Y")/$(date -d "yesterday" +"%m")
#set nginx log files you want to cut
log_files_name=(access)
#set the path to nginx.
nginx_sbin="/usr/local/nginx/sbin/nginx"
#Set how long you want to save
save_days=30
############################################
#Please do not modify the following script #
############################################
mkdir -p $log_files_dir
log_files_num=${#log_files_name[@]}
#cut nginx log files
for((i=0;i<$log_files_num;i++));do
mv ${log_files_path}${log_files_name[i]}.log ${log_files_dir}/${log_files_name[i]}_$(date -d "yesterday" +"%Y%m%d").log
done
#delete 30 days ago nginx log files
find $log_files_path -mtime +$save_days -exec rm -rf {} \;
$nginx_sbin -s reloadIV. 脚本概括及可能会遇到的挫折
一共会使用到三个脚本:分别依次执行,archives.count.sh(分析 access.log、统计数据;计为新增,add)、archives.slug.sh(导出原始数据库数据,计为原始,origin)、archives.count.all.sh(原始与新增进行加和,计为全部,all,并写入MySQL);
V. 分析、抓取日志以获取文章新增阅读数(第一步)
抓取当天符合一定条件下的日志记录;
1.机器人访问的日志丢弃;
2.同页面同IP多次访问去重只取一次访问的值;
3.排除特定的请求方法如head/post等非get请求;
4.IPv4/IPv6地址的过滤;
5.正确的使用到正则表达式(grep)点此学习;
以下脚本命名为:archives.count.sh;
#!/bin/bash
rm /home/wwwlogs/limbopro.com/log/*;
rm /home/wwwlogs/limbopro.com/access.archives;
rm /home/wwwlogs/limbopro.com/access.archives.filter;
rm /home/wwwlogs/limbopro.com/archives.id;
rm /home/wwwlogs/limbopro.com/archives.id.count.origin;
rm /home/wwwlogs/limbopro.com/archives.id.count.add;
rm /home/wwwlogs/limbopro.com/archives.id.count.all;
rm /home/wwwlogs/limbopro.com/archives.id.count.add.title;
rm /home/wwwlogs/limbopro.com/yesterday.views.txt;
#logpath='/home/wwwlogs/limbopro.com/2021/01/access_20210126.log' #日志位置
logpath='/home/wwwlogs/limbopro.com/access.log' #日志位置
slugpath='/home/wwwlogs/limbopro.com/log/' #slug 访问IP记录临时存放位置(自定义)
mysqlpasswd='114154' #''号内填写数据库密码
addnotes='/home/wwwlogs/limbopro.com/yesterday.views.txt' # 新增阅读数/Slug/文章名称 数据存放位置
grep -o -P "(?:(?<=/)|(?<=archives/))(\w{1,50}|(\w{1,50}-){1,10}\w{1,50})(?=\.html\s.*?200)" $logpath >> /home/wwwlogs/limbopro.com/access.archives #过滤出文章slug
cat /home/wwwlogs/limbopro.com/access.archives | sort | uniq >> /home/wwwlogs/limbopro.com/access.archives.filter #文章slug去重
IPADDR=$(</home/wwwlogs/limbopro.com/access.archives.filter)
for IPADDR in ${IPADDR[@]}; do
## Part1 统计新增阅读数
#IPv4 grep -o -P "(\w{1,3}\.){3}\w{1,3}(?=\b.*?GET.*?/$IPADDR\.html.*?200)(?!(.*?Googlebot|.*?bot|.*?Bot))" $logpath > $slugpath$IPADDR; #过滤出对应文章slug下的ip数
#IPv6 grep -o -P "((\w{1,3}\.){3}\w{1,3}|(\w{4}:){2}:(\w{4}:){3}\w{4})(?=\b.*?GET.*?/$IPADDR\.html.*?200)(?!(.*?Googlebot|.*?bot|.*?Bot|.*?Wget))" $logpath > $slugpath$IPADDR; #过滤出对应文章slug下的ip数
grep -o -P "((\w{1,3}\.){3}\w{1,3}|((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))))(?=\b.*?GET.*?/$IPADDR\.html.*?200)(?!(.*?Googlebot|.*?bot|.*?Bot|.*?Wget))" $logpath > $slugpath$IPADDR; #过滤出对应文章slug下的ip数
ipcounts=$(awk '{print $1}' /home/wwwlogs/limbopro.com/log/$IPADDR | sort -n | uniq | wc -l); #去重并计算IP数量
echo $IPADDR >> /home/wwwlogs/limbopro.com/archives.id #输出文章 slug
echo $IPADDR $ipcounts >> /home/wwwlogs/limbopro.com/archives.id.count.add # 输出文章slug及新增IP访问数量
## Part2 生成报表
MYSQL="mysql -hlocalhost -uroot -p$mysqlpasswd --default-character-set=utf8 -A -N" # 输入密码
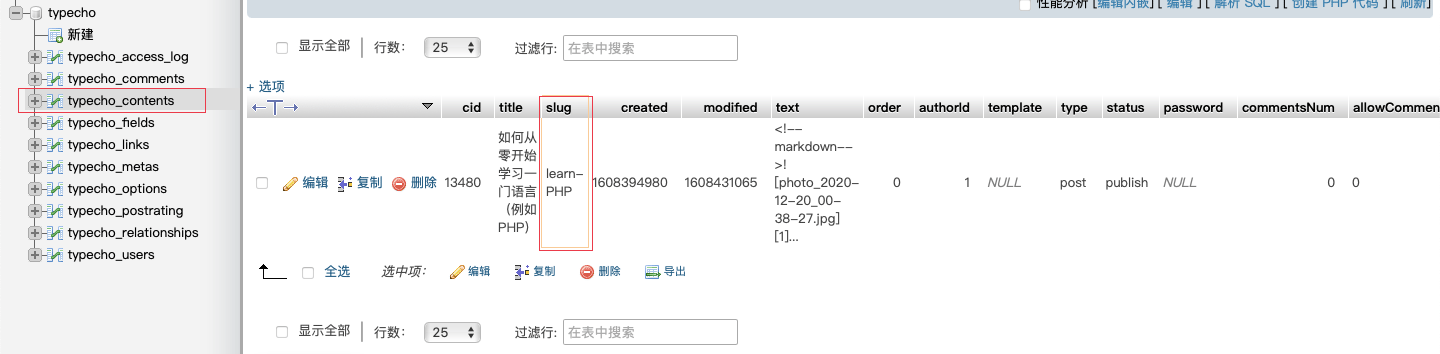
sql2="select title from typecho.typecho_contents where slug = '$IPADDR';" # 提取标题
result2="$($MYSQL -e "$sql2")" # 提取标题
echo $ipcounts $IPADDR $result2 >> $addnotes; # 文章名称及新增阅读数
done
/home/wwwlogs/limbopro.com/archives.slug.sh >> /home/wwwlogs/limbopro.com/archives.id.count.origin;
/home/wwwlogs/limbopro.com/archives.count.all.sh;VI. 读取MySQL views 字段值以获取原始阅读数(第二步)
获取并统计原始阅读数;根据 slug 字段值,读取 views 字段值(统计文章原始阅读数);
以下脚本命名为:archives.slug.sh;
#!/bin/bash
mysqlpasswd='114154' #''号内填写数据库密码
tpcontents=typecho.typecho_contents
IPADDR=$(</home/wwwlogs/limbopro.com/archives.id)
for IPADDR in ${IPADDR[@]}; do
MYSQL="mysql -hlocalhost -uroot -p$mysqlpasswd --default-character-set=utf8 -A -N"
sql="select views from $tpcontents where slug = '$IPADDR';"
result="$($MYSQL -e "$sql")"
echo $IPADDR $result;
doneVII. 统计新增+原始阅读数(第三步)
以下脚本命名为:archives.count.all.sh;
#!/bin/bash
> /home/wwwlogs/limbopro.com/archives.id.count.all;
mysqlpasswd='114154' #''号内填写数据库密码
tpcontents=typecho.typecho_contents;
IPADDR=$(</home/wwwlogs/limbopro.com/archives.id)
for IPADDR in ${IPADDR[@]}; do
orgin=$(grep -o -P "(?<=^$IPADDR\s).*" /home/wwwlogs/limbopro.com/archives.id.count.origin);
add=$(grep -o -P "(?<=^$IPADDR\s).*" /home/wwwlogs/limbopro.com/archives.id.count.add);
new=`expr $orgin + $add`
echo $IPADDR $new >> /home/wwwlogs/limbopro.com/archives.id.count.all
MYSQL="mysql -hlocalhost -uroot -p$mysqlpasswd --default-character-set=utf8 -A -N"
sql="UPDATE $tpcontents SET views='$new' WHERE slug='$IPADDR';"
result="$($MYSQL -e "$sql")"
doneVIII. 设置定时执行命令(crontab)
crontab 命令操作指引:Linux crontab 命令;
root@localhost:~#crontab -e
#新增一条定时执行命令
55 23 * * * /home/wwwlogs/limbopro.com/archives.count.sh; #每晚11点55分更新阅读数;好了,以上;
版权属于:毒奶
联系我们:https://limbopro.com/6.html
毒奶搜索:https://limbopro.com/search.html
毒奶导航:https://limbopro.com/daohang/index.html本文链接:https://limbopro.com/archives/13491.html
本文采用 CC BY-NC-SA 4.0 许可协议,转载或引用本文时请遵守许可协议,注明出处、不得用于商业用途!




